Ellie Li
Master | Data Science, WPI
Master | Data Science, WPI

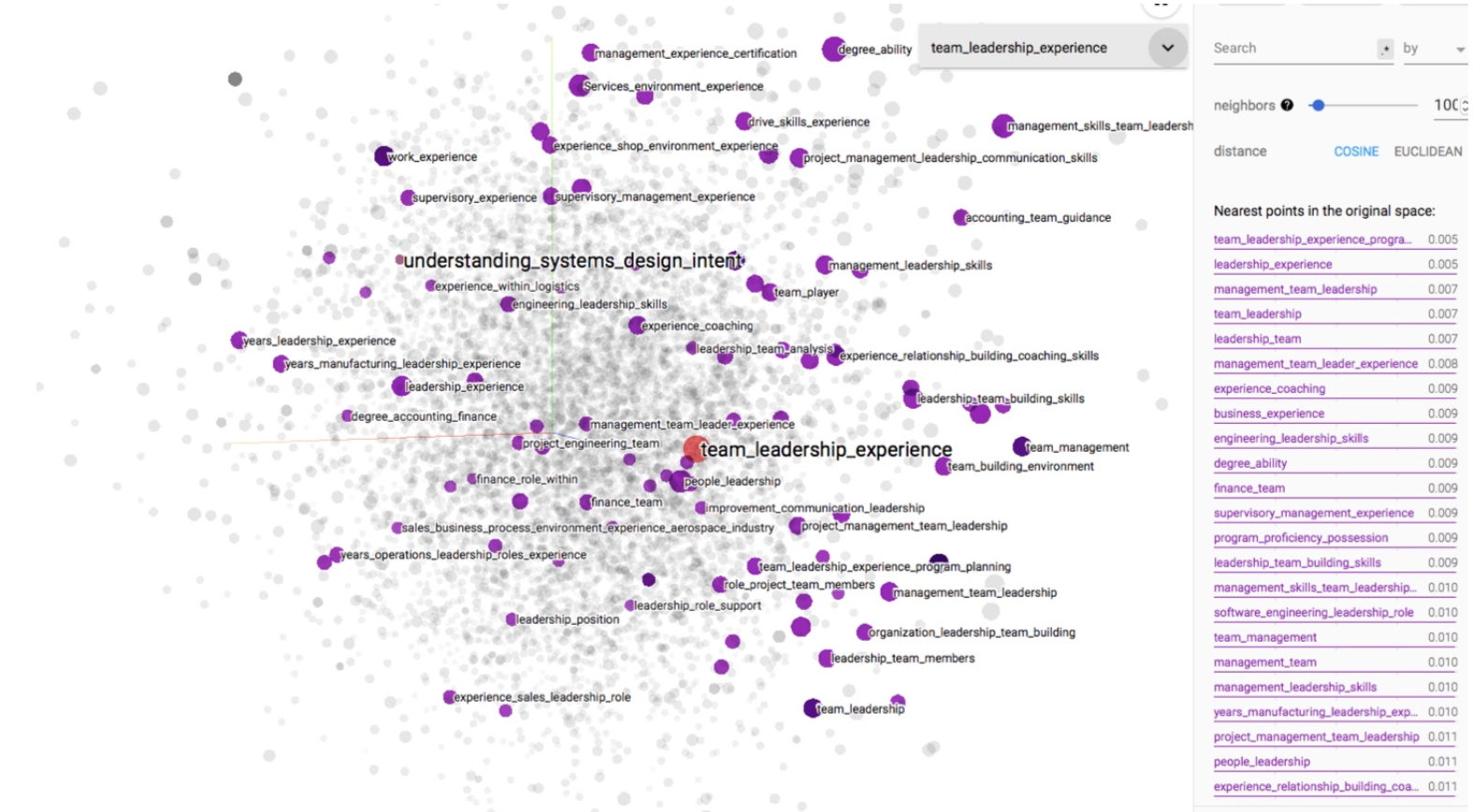
"Very cool. Thank you for sharing. The first match sounds like it aligned best with me!"
“I think this is a very powerful tool! I think with the resume I sent to you I would most definitely apply to this job as it touches on a lot of the skills that I listed…"
"All are jobs that would fit my background, but I personally know I wouldn’t want to work in those roles."
"I think the first 3 JD match my profile but not so much the fourth one."
"I went through the 5 recommendations and have some feedback : 1 - Poor Match, 2 - Good Match, 3 - Poor Match, 4 - Worst Match, 5 - Best Match."


A Joint Classification-Regression Model of Predicting Spenders and Revenue for Google Store
View More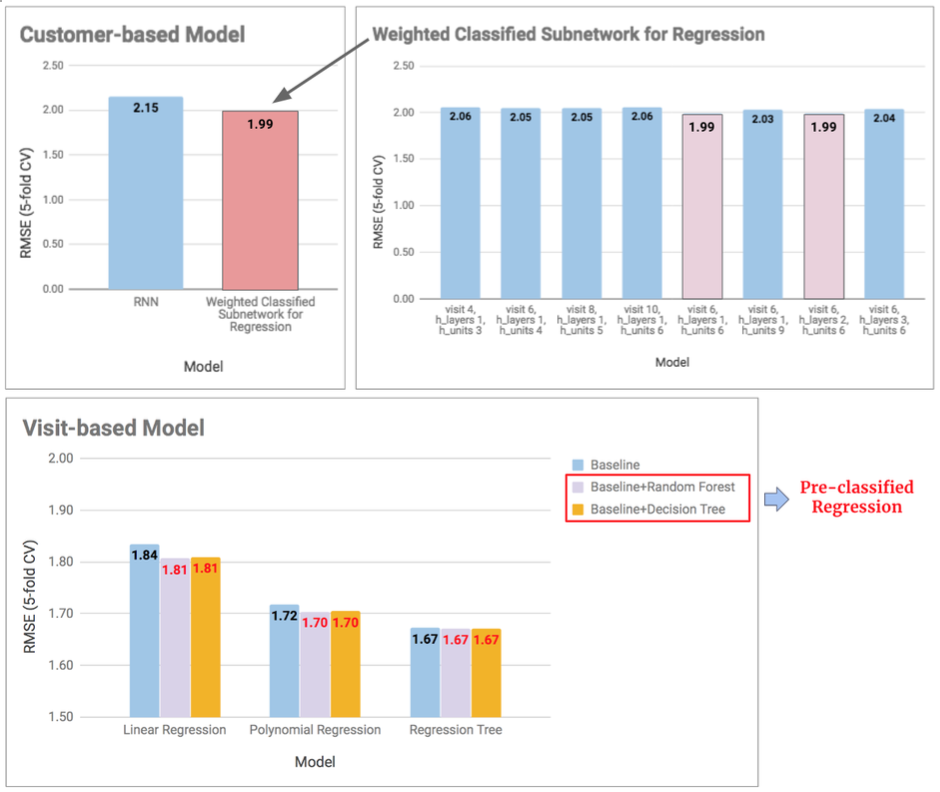

Automate the Scheduling Process of Campus Event with Artificial Intelligence
View More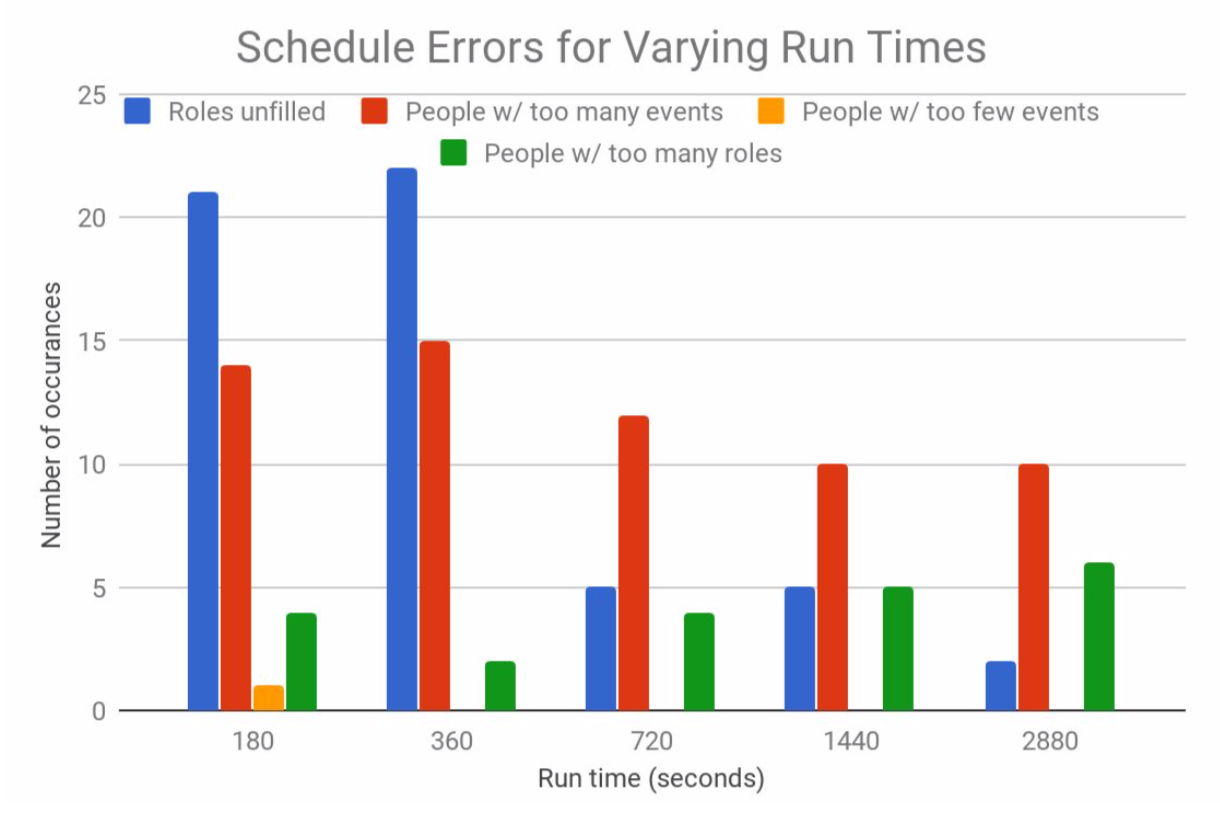
For evaluation, currently we are only using categories like number of people with too many/few hours, number of people with too many roles filled, but this could not evaluate how a schedule actually works. For example, a schedule with 10 people of 2 hours exceeding the expected working hours is definitely better than a schedule with 10 people of 10 hours exceeding the expected working hours. By improving the strategy for evaluating schedules, we could collect more data for tuning the heuristic to produce even better outcomes.