# coding: utf-8
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import random
from sklearn.metrics import mean_squared_error
# Import data sets
processed_train_df = pd.read_csv("/Users/ying/2018Fall/CS539/Project/CS539_ML-master-2/processed_train_df.csv", dtype={'fullVisitorId': 'str'})
# Drop the index column
processed_train_df = processed_train_df.drop('Unnamed: 0', axis=1)
print("Train DataFrame Shape: " + str(processed_train_df.shape))
processed_train_df.head()
# Utilities
# 5-fold cross validation
unique_visitorId = processed_train_df['fullVisitorId'].unique()
random.seed(123)
random.shuffle(unique_visitorId)
no_cust = len(unique_visitorId)
print(no_cust)
fold = 5
id_cv = []
for i in range(fold):
if i < fold-1:
cur_cv = unique_visitorId[i*(no_cust//5):(i+1)*(no_cust//5)]
else:
cur_cv = unique_visitorId[i*(no_cust//5):no_cust]
id_cv.append(cur_cv)
# Calculate RMSE based on the natural log of the predicted revenue for a customer.
def getMse(x_tr, train, val, log_y_tr_pred, log_y_val_pred):
revenue = np.exp(log_y_tr_pred) - 1
id_list = list(train['fullVisitorId'])
d = {'fullVisitorId':id_list, 'PredictedRevenue':revenue}
submit = pd.DataFrame(data=d)
col = ['fullVisitorId', 'PredictedRevenue']
submit = submit[col]
submit = pd.DataFrame(submit.groupby('fullVisitorId')["PredictedRevenue"].sum().reset_index())
submit['PredictedLogRevenue'] = np.log1p(submit['PredictedRevenue'])
y_tr_pred = list(submit['PredictedLogRevenue'])
y_train_sumrev = pd.DataFrame(train.groupby('fullVisitorId')["totals.transactionRevenue"].sum().reset_index())
y_train_sumrev['totals.transactionRevenue'] = np.log1p(y_train_sumrev['totals.transactionRevenue'])
y_tr = list(y_train_sumrev['totals.transactionRevenue'])
mse_tr = mean_squared_error(y_tr, y_tr_pred)
print('train_mse', mse_tr)
print('train_rmse', np.sqrt(mse_tr))
revenue = np.exp(log_y_val_pred) - 1
id_list = list(val['fullVisitorId'])
d = {'fullVisitorId':id_list, 'PredictedRevenue':revenue}
submit = pd.DataFrame(data=d)
col = ['fullVisitorId', 'PredictedRevenue']
submit = submit[col]
submit = pd.DataFrame(submit.groupby('fullVisitorId')["PredictedRevenue"].sum().reset_index())
submit['PredictedLogRevenue'] = np.log1p(submit['PredictedRevenue'])
y_val_pred = list(submit['PredictedLogRevenue'])
y_val_sumrev = pd.DataFrame(val.groupby('fullVisitorId')["totals.transactionRevenue"].sum().reset_index())
y_val_sumrev['totals.transactionRevenue'] = np.log1p(y_val_sumrev['totals.transactionRevenue'])
y_val = list(y_val_sumrev['totals.transactionRevenue'])
mse_val = mean_squared_error(y_val, y_val_pred)
print('val_mse', mse_val)
print('val_rmse', np.sqrt(mse_val))
return mse_tr, mse_val
# Baseline1 -- Linear Regression
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
train_mse = []
train_rmse = []
val_mse = []
val_rmse = []
for i in range(fold):
print('\n\nfold:', i)
val = processed_train_df[processed_train_df['fullVisitorId'].isin(id_cv[i])]
train = processed_train_df[~processed_train_df['fullVisitorId'].isin(id_cv[i])]
x_tr = train.iloc[:,2:]
y_tr = train.iloc[:,1]
log_y_tr = np.log1p(y_tr)
x_val = val.iloc[:,2:]
y_val = val.iloc[:,1]
log_y_val = np.log1p(y_val)
# --- INSERT YOUR MODEL -----
model = LinearRegression().fit(x_tr, log_y_tr)
log_y_tr_pred = model.predict(x_tr)
# ---------------------------
log_y_tr_pred = [0 if i < 0 else i for i in log_y_tr_pred]
log_y_val_pred = model.predict(x_val)
log_y_val_pred = [0 if i < 0 else i for i in log_y_val_pred]
mse_tr, mse_val = getMse(x_tr, train, val, log_y_tr_pred, log_y_val_pred)
train_mse.append(mse_tr)
train_rmse.append(np.sqrt(mse_tr))
val_mse.append(mse_val)
val_rmse.append(np.sqrt(mse_val))
print('\n\nAverage:')
print('train_mse_5fold', np.mean(train_mse))
print('train_rmse_5fold', np.mean(train_rmse))
print('val_mse_5fold', np.mean(val_mse))
print('val_rmse_5fold', np.mean(val_rmse))
# Baseline2 -- Polynomial Regression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
train_mse = []
train_rmse = []
val_mse = []
val_rmse = []
for i in range(fold):
print('\n\nfold:', i)
val = processed_train_df[processed_train_df['fullVisitorId'].isin(id_cv[i])]
train = processed_train_df[~processed_train_df['fullVisitorId'].isin(id_cv[i])]
x_tr = train.iloc[:,2:]
y_tr = train.iloc[:,1]
log_y_tr = np.log1p(y_tr)
x_val = val.iloc[:,2:]
y_val = val.iloc[:,1]
log_y_val = np.log1p(y_val)
# --- INSERT YOUR MODEL -----
model_pipeline = Pipeline([('poly',PolynomialFeatures(degree=2)),
('linear', LinearRegression(fit_intercept=False))])
model = model_pipeline.fit(x_tr, log_y_tr)
log_y_tr_pred = model.predict(x_tr)
# ---------------------------
log_y_tr_pred = [0 if i < 0 else i for i in log_y_tr_pred]
log_y_val_pred = model.predict(x_val)
log_y_val_pred = [0 if i < 0 else i for i in log_y_val_pred]
mse_tr, mse_val = getMse(x_tr, train, val, log_y_tr_pred, log_y_val_pred)
train_mse.append(mse_tr)
train_rmse.append(np.sqrt(mse_tr))
val_mse.append(mse_val)
val_rmse.append(np.sqrt(mse_val))
print('\n\nAverage:')
print('train_mse_5fold', np.mean(train_mse))
print('train_rmse_5fold', np.mean(train_rmse))
print('val_mse_5fold', np.mean(val_mse))
print('val_rmse_5fold', np.mean(val_rmse))
# Baseline3 -- Regression Tree
from sklearn.tree import DecisionTreeRegressor
train_mse = []
train_rmse = []
val_mse = []
val_rmse = []
for i in range(fold):
print('\n\nfold:', i)
val = processed_train_df[processed_train_df['fullVisitorId'].isin(id_cv[i])]
train = processed_train_df[~processed_train_df['fullVisitorId'].isin(id_cv[i])]
x_tr = train.iloc[:,2:]
y_tr = train.iloc[:,1]
log_y_tr = np.log1p(y_tr)
x_val = val.iloc[:,2:]
y_val = val.iloc[:,1]
log_y_val = np.log1p(y_val)
# --- INSERT YOUR MODEL -----
model = DecisionTreeRegressor(max_depth=10)
model.fit(x_tr, log_y_tr)
log_y_tr_pred = model.predict(x_tr)
# ---------------------------
log_y_tr_pred = [0 if i < 0 else i for i in log_y_tr_pred]
log_y_val_pred = model.predict(x_val)
log_y_val_pred = [0 if i < 0 else i for i in log_y_val_pred]
mse_tr, mse_val = getMse(x_tr, train, val, log_y_tr_pred, log_y_val_pred)
train_mse.append(mse_tr)
train_rmse.append(np.sqrt(mse_tr))
val_mse.append(mse_val)
val_rmse.append(np.sqrt(mse_val))
print('\n\nAverage:')
print('train_mse_5fold', np.mean(train_mse))
print('train_rmse_5fold', np.mean(train_rmse))
print('val_mse_5fold', np.mean(val_mse))
print('val_rmse_5fold', np.mean(val_rmse))
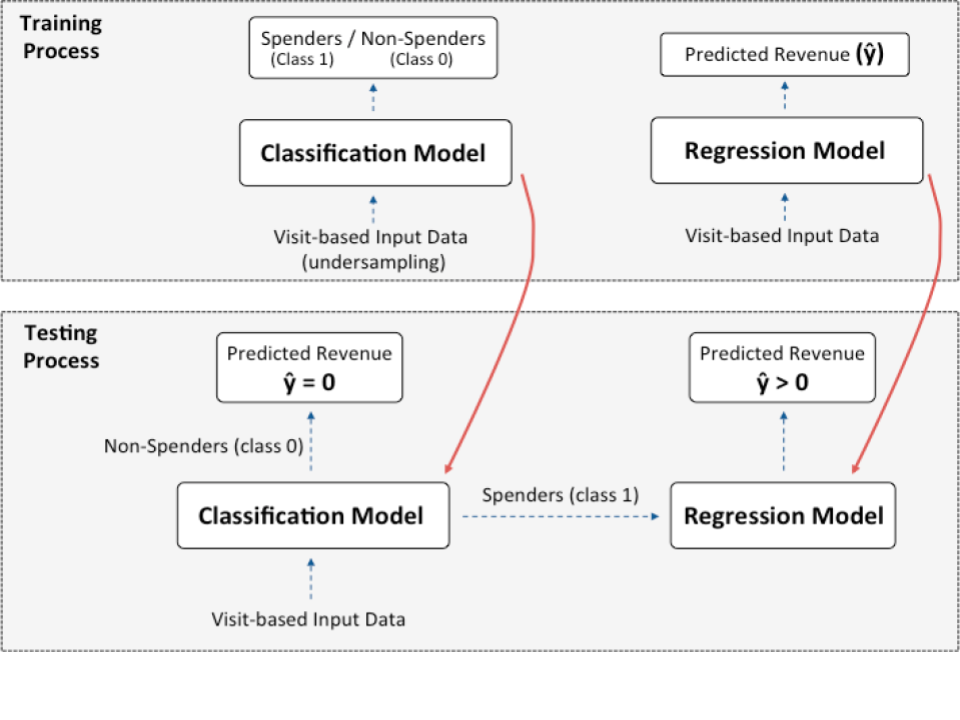
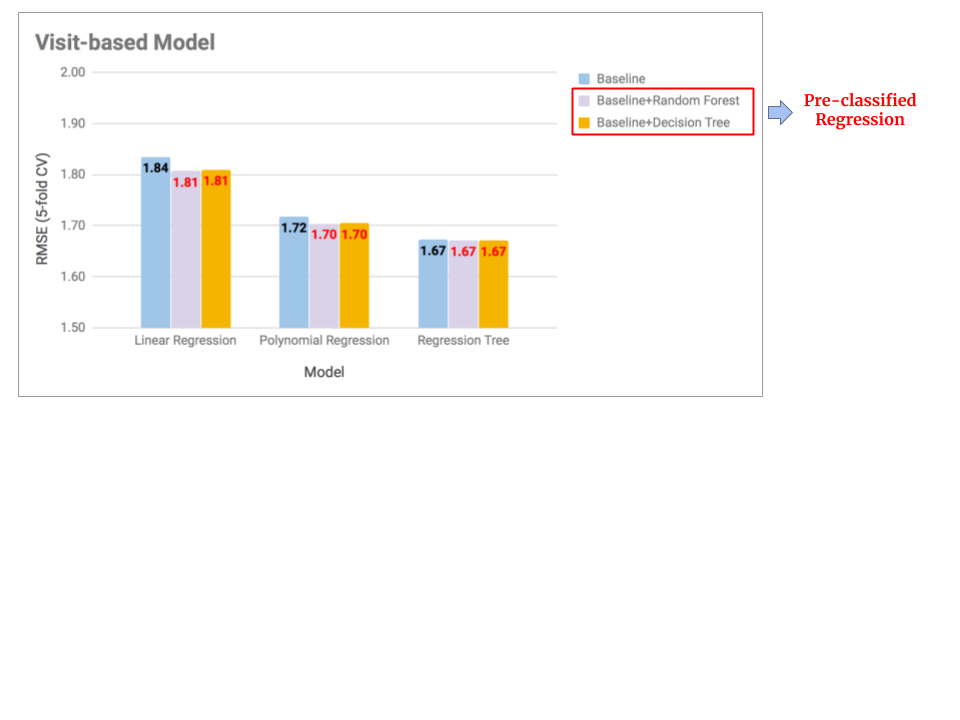
# Pre-classed Regression
# Add classification lables: nonzero-revenue as "1"; zero-revenue as "0"
processed_train_df['clf_label'] = np.where(processed_train_df['totals.transactionRevenue']==0.0, 0, 1)
processed_train_df.head()
# Model Implementation
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
from sklearn.tree import DecisionTreeRegressor
train_mse = []
train_rmse = []
val_mse = []
val_rmse = []
feature_list = [k for k in list(processed_train_df) if k not in ['fullVisitorId', 'totals.transactionRevenue', 'clf_label']]
for i in range(fold):
print('\n\nfold:', i)
val = processed_train_df[processed_train_df['fullVisitorId'].isin(id_cv[i])]
train = processed_train_df[~processed_train_df['fullVisitorId'].isin(id_cv[i])]
x_val = val[feature_list]
y_clf_val = val['clf_label']
y_val = val.iloc[:,1]
log_y_val = np.log1p(y_val)
nonzero_sample = train.loc[train[train['totals.transactionRevenue'] != 0.0].index]
zero_indices = train[train['totals.transactionRevenue'] == 0.0].index
random_indices = np.random.choice(zero_indices, nonzero_sample.shape[0], replace=False)
zero_sample = train.loc[random_indices]
undersampled_train_df = pd.concat([nonzero_sample, zero_sample])
x_tr = undersampled_train_df[feature_list]
y_clf_tr = undersampled_train_df['clf_label']
y_tr = undersampled_train_df.iloc[:,1]
log_y_tr = np.log1p(y_tr)
nonzero_index_tr = []
nonzero_index_val = []
# ----- Insert Classification Model Here-----
model = DecisionTreeClassifier(max_depth=8)
# model = RandomForestClassifier(n_estimators=150, max_depth=15)
# model = LogisticRegression(class_weight="balanced", solver='liblinear')
# -------------------------------------------
model.fit(x_tr, y_clf_tr)
y_clf_tr_pred = model.predict(x_tr)
y_clf_val_pred = model.predict(x_val)
for m in range(len(y_clf_tr_pred)):
if y_clf_tr_pred[m] == 0:
continue
else:
nonzero_index_tr.append(m)
x_regr_tr = x_tr.iloc[nonzero_index_tr]
y_regr_tr = undersampled_train_df.iloc[nonzero_index_tr,1]
log_y_tr = np.log1p(y_regr_tr)
for j in range(len(y_clf_val_pred)):
if y_clf_val_pred[j] == 0:
continue
else:
nonzero_index_val.append(j)
x_regr_val = x_val.iloc[nonzero_index_val,]
y_regr_val = val.iloc[nonzero_index_val,1]
log_y_val = np.log1p(y_regr_val)
x_tr1 = train[feature_list]
y_tr1 = train.iloc[:,1]
log_y_tr1 = np.log1p(y_tr1)
# ----- Insert Regression Model Here-----
model = DecisionTreeRegressor(max_depth=8).fit(x_tr1, log_y_tr1)
# model_pipeline = Pipeline([('poly',PolynomialFeatures(degree=2)),
# ('linear', LinearRegression(fit_intercept=False))])
# model = model_pipeline.fit(x_tr1, log_y_tr1)
# model = LinearRegression().fit(x_tr1, log_y_tr1)
# ---------------------------------------
log_y_tr_pred = model.predict(x_regr_tr)
tr_pred = list(0 for i in range(len(x_tr)))
num = 0
for index in nonzero_index_tr:
tr_pred[index] = log_y_tr_pred[num]
num += 1
tr_pred = [0 if i < 0 else i for i in tr_pred]
log_y_val_pred = model.predict(x_regr_val)
val_pred = list(0 for i in range(len(x_val)))
num = 0
for index in nonzero_index_val:
val_pred[index] = log_y_val_pred[num]
num += 1
val_pred = [0 if i < 0 else i for i in val_pred]
mse_tr, mse_val = getMse(x_tr, undersampled_train_df, val, tr_pred, val_pred)
train_mse.append(mse_tr)
train_rmse.append(np.sqrt(mse_tr))
val_mse.append(mse_val)
val_rmse.append(np.sqrt(mse_val))
print('\n\nAverage:')
print('val_mse_5fold', np.mean(val_mse))
print('val_rmse_5fold', np.mean(val_rmse))