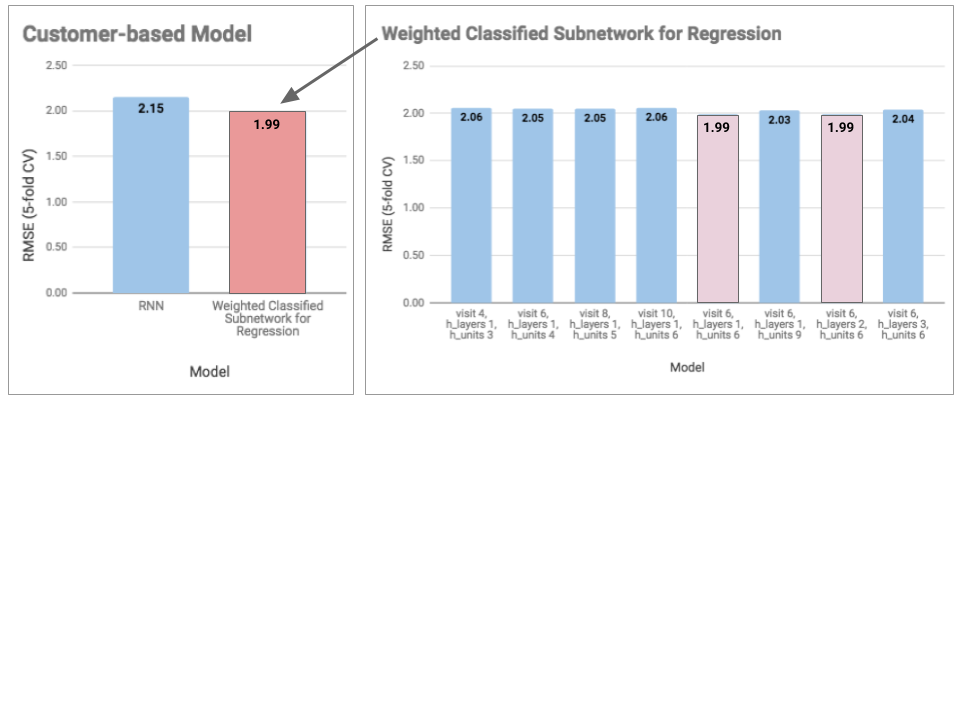
Including baselines and the proposed model - Weighted Classified Subnetwork for Regression
import matplotlib.pyplot as plt
plt.switch_backend('agg')
import matplotlib.pylab as pylab
params = {'legend.fontsize': 'x-large',
'axes.labelsize': 'x-large',
'axes.titlesize':'x-large',
'xtick.labelsize':'x-large',
'ytick.labelsize':'x-large'}
pylab.rcParams.update(params)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import random
import ast
class get_plot:
def __init__(self, method, data, exp, plot_loss, losses, plot_acc, train_acc_ep,
test_acc_ep):
self.method = method
self.data = data
self.exp = exp
self.plot_loss = plot_loss
self.losses = losses
self.plot_acc = plot_acc
self.train_acc_ep = train_acc_ep
self.test_acc_ep = test_acc_ep
self.get_plot_fn()
def get_plot_fn(self):
if self.plot_loss:
plt.plot(self.losses)
plt.ylabel('loss_'+self.method)
plt.xlabel('epoch')
plt.show()
self.plt_name = "result_Main"+self.data+"_Ex"+ str(self.exp)+"_Loss"
+ self.method+".png"
plt.savefig(self.plt_name, bbox_inches='tight')
plt.clf()
if self.plot_acc:
plt.subplot(223)
#plt.ylim([0, 105])
plt.plot(self.train_acc_ep, 'b-', label='training')
plt.plot(self.test_acc_ep, 'r--', label='testing')
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
plt.ylabel('RMSE')
plt.xlabel('epoch')
plt.show()
self.plt_name = "result_Main"+self.data+"_Ex"+ str(self.exp)+"_RMSE"
+ self.method+".png"
plt.savefig(self.plt_name, bbox_inches='tight')
def strToList(a_str):
return ast.literal_eval(a_str)
class data_paddle:
def __init__(self, data_vec, visit = 4):
self.visit = visit
self.data_vec = data_vec
self.data_paddle_fn()
def data_paddle_fn(self):
self.data_pad = []
if len(self.data_vec) > self.visit :
self.data_pad = self.data_vec[-self.visit:]
else :
for i in range(self.visit - len(self.data_vec)):
self.data_pad.append([0]*(len(self.data_vec[0])))
self.data_pad = self.data_pad+self.data_vec
return self.data_pad
class LSTMmodel(nn.Module):
def __init__(self, num_layers, input_size, batchsize, hidden_size, output_size,
seq_len):
super(LSTMmodel, self).__init__()
torch.manual_seed(1)
self.num_layers = num_layers
self.input_size = input_size
self.batchsize = batchsize
self.hidden_size = hidden_size
self.output_size = output_size
self.seq_len = seq_len
self.rnn = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers)
self.linear = nn.Linear(hidden_size, 1)
def forward(self, input_data):
self.h0 = autograd.Variable(torch.randn(self.num_layers, self.batchsize,
self.hidden_size))
self.c0 = autograd.Variable(torch.randn(self.num_layers, self.batchsize,
self.hidden_size))
self.output, self.hn = self.rnn(input_data, (self.h0, self.c0))
self.last_hidden = self.output[-1]
self.y_hat = self.linear(self.last_hidden)
return self.y_hat
def run_trainer(train_df,test_df,num_layers,input_size,hidden_size,output_size,
seq_len,epoch_num,batchsize,lr):
train_sample = len(train_df)
test_sample = len(test_df)
model = LSTMmodel(num_layers, input_size, batchsize, hidden_size, output_size,
seq_len)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=lr)
losses = []
iterative = train_sample//batchsize if train_sample/batchsize
== int(train_sample//batchsize) else train_sample//batchsize + 1
iter_test = test_sample//batchsize if test_sample/batchsize
== int(test_sample//batchsize) else test_sample//batchsize + 1
train_mse = []
train_rmse = []
test_mse = []
test_rmse = []
for epoch in range(epoch_num):
verbose = True if epoch/1000 == int(epoch//1000) else False
if verbose: print('epoch', epoch, end=' ')
train_preds = np.array([])
test_preds = np.array([])
epoch_loss = 0
train_df_shuffle = train_df.sample(frac=1)
np.array(train_df)[:,1]
for j in range(0,iterative-1):
batch = train_df_shuffle.iloc[(batchsize*j):min(batchsize*(j+1),
train_sample),:]
batch_input = batch['combine']
batch_label = batch['totals.transactionRevenue']
batch_input = np.array([i for i in batch_input.values])
batch_input.shape
batch_input = np.transpose(batch_input,(1,0,2))
tf_input = autograd.Variable(torch.FloatTensor(batch_input),
requires_grad=True)
model.zero_grad()
yhat = model.forward(tf_input)
batch_label = np.array([i for i in batch_label.values]).reshape(
(batchsize,1))
tf_label = autograd.Variable(torch.FloatTensor(batch_label))
loss = loss_fn(yhat,tf_label)
loss.backward()
optimizer.step()
epoch_loss += float(loss.data)
train_preds = np.concatenate((train_preds,yhat.view(-1).detach().numpy
()), axis=0)
if j == 0: train_y = tf_label.view(-1).detach().numpy()
else: train_y = np.concatenate((train_y,tf_label.view(-1).detach()
.numpy()), axis=0)
losses.append(epoch_loss)
if verbose: print('epoch_loss', np.round(epoch_loss,4), end=' ')
# --- epoch MSE training
train_mse.append(mean_squared_error(train_y,train_preds))
train_rmse.append(np.sqrt(mean_squared_error(train_y,train_preds)))
if verbose: print('train_rmse',
np.round(np.sqrt(mean_squared_error(train_y,train_preds)),4),
end=' ')
for j in range(0,iter_test):
test_batch = test_df.iloc[(batchsize*j):min(batchsize*(j+1),len
(test_df))]
test_batch_input = test_batch['combine']
test_batch_label = test_batch['totals.transactionRevenue']
test_batch_input = np.array([i for i in test_batch_input.values])
test_batch_input = np.transpose(test_batch_input,(1,0,2))
tf_input = autograd.Variable(torch.FloatTensor(batch_input),
requires_grad=True)
yhat = model.forward(tf_input)
test_batch_label = np.array([i for i in test_batch_label.values])
.reshape((batchsize,1))
tf_label = autograd.Variable(torch.FloatTensor(test_batch_label))
test_preds = np.concatenate((test_preds,yhat.view(-1).detach().numpy())
, axis=0)
if j == 0: test_y = tf_label.view(-1).detach().numpy()
else: test_y = np.concatenate((test_y,tf_label.view(-1).detach().numpy
()), axis=0)
# --- epoch accuracy testing
test_mse.append(mean_squared_error(test_y,test_preds))
test_rmse.append(np.sqrt(mean_squared_error(test_y,test_preds)))
if verbose: print('test_rmse', np.round(np.sqrt(mean_squared_error(test_y,
test_preds)),4))
return losses, train_mse, train_rmse, test_mse, test_rmse
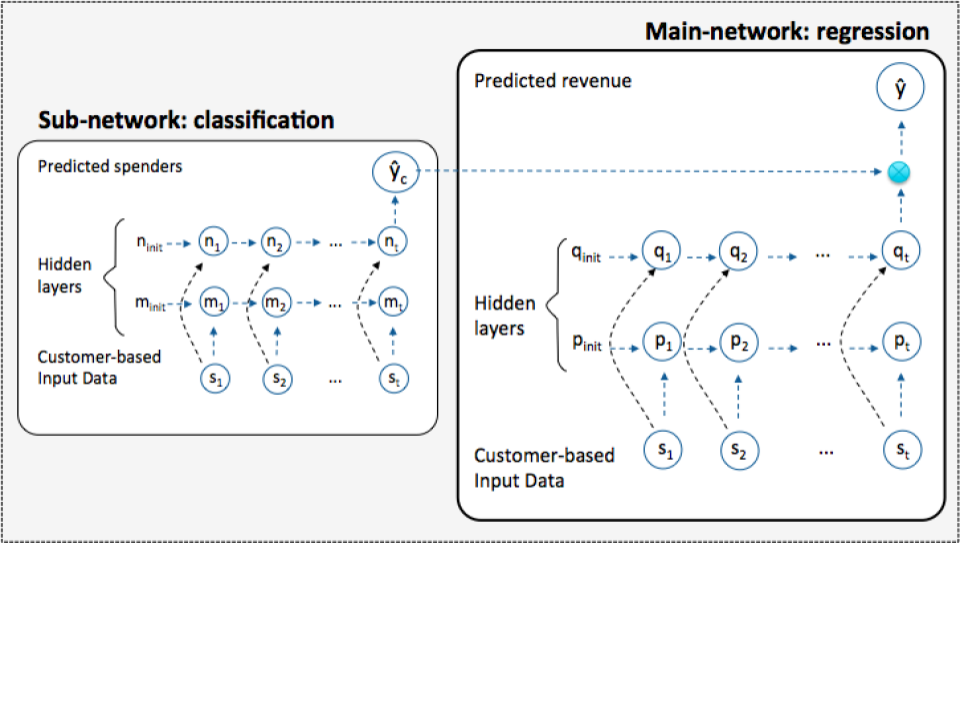
class weightedCF_rnn(nn.Module):
def __init__(self, seq_len, no_class, param_cf, param_reg):
super(weightedCF_rnn, self).__init__()
torch.manual_seed(1)
self.seq_len = seq_len
# param for cf
self.no_class = no_class
self.num_layers_cf = param_cf['num_layers']
self.input_size_cf = param_cf['input_size']
self.batchsize_cf = param_cf['batchsize']
self.hidden_size_cf = param_cf['hidden_size']
self.rnn_cf = nn.LSTM(input_size=self.input_size_cf,
hidden_size=self.hidden_size_cf,
num_layers=self.num_layers_cf)
self.linear_cf = nn.Linear(self.hidden_size_cf, self.no_class)
self.softmax_cf = nn.Softmax(dim=-1)
self.crossENTloss = nn.CrossEntropyLoss()
# param for reg
self.num_layers_reg = param_reg['num_layers']
self.input_size_reg = param_reg['input_size']
self.batchsize_reg = param_reg['batchsize']
self.hidden_size_reg = param_reg['hidden_size']
self.output_size_reg = param_reg['output_size']
self.seq_len = seq_len
self.rnn_reg = nn.LSTM(input_size=self.input_size_reg,
hidden_size=self.hidden_size_reg,
num_layers=self.num_layers_reg)
self.linear_reg = nn.Linear(self.hidden_size_reg, 1)
self.mseloss = nn.MSELoss()
def forward(self, input_data, label_cf, label_reg):
# -- weighted CF
self.h0_cf = autograd.Variable(torch.randn(self.num_layers_cf ,
self.batchsize_cf ,
self.hidden_size_cf))
self.c0_cf = autograd.Variable(torch.randn(self.num_layers_cf ,
self.batchsize_cf ,
self.hidden_size_cf))
self.output_cf, self.hn_cf = self.rnn_cf(input_data, (self.h0_cf,
self.c0_cf))
self.last_hidden_cf = self.output_cf[-1]
self.h_cf = self.linear_cf(self.last_hidden_cf)
self.y_hat_cf = self.softmax_cf(self.h_cf)
self.loss_cf = self.crossENTloss(self.y_hat_cf, label_cf)
# -- regression
self.h0_reg = autograd.Variable(torch.randn(self.num_layers_reg,
self.batchsize_reg,
self.hidden_size_reg))
self.c0_reg = autograd.Variable(torch.randn(self.num_layers_reg,
self.batchsize_reg,
self.hidden_size_reg))
self.output_reg, self.hn_reg = self.rnn_reg(input_data, (self.h0_reg,
self.c0_reg))
self.last_hidden_reg = self.output_reg[-1]
self.weight = self.y_hat_cf[:,1].view(self.batchsize_cf,1)
self.y_hat_reg = self.weight*self.linear_reg(self.last_hidden_reg)
self.loss_reg = self.mseloss(self.y_hat_reg, label_reg)
# -- final loss
self.loss = self.loss_cf + self.loss_reg
return self.loss, self.y_hat_cf, self.y_hat_reg
def train_rnnCF(train_df, test_df, seq_len, epoch_num, lr, no_class, param_cf,
param_reg):
train_sample = len(train_df)
test_sample = len(test_df)
batchsize = param_cf['batchsize']
model = weightedCF_rnn(seq_len, no_class, param_cf, param_reg)
optimizer = optim.SGD(model.parameters(), lr=lr)
losses = []
iterative =
train_sample//batchsize if train_sample/batchsize
== int(train_sample//batchsize) else train_sample//batchsize + 1
iter_test =
test_sample//batchsize if test_sample/batchsize
== int(test_sample//batchsize) else test_sample//batchsize + 1
train_mse = []
train_rmse = []
test_mse = []
test_rmse = []
for epoch in range(epoch_num):
verbose = True if epoch/1000 == int(epoch//1000) else False
if verbose: print('epoch', epoch, end=' ')
train_preds = np.array([])
test_preds = np.array([])
epoch_loss = 0
train_df_shuffle = train_df.sample(frac=1)
for j in range(0,iterative-1):
batch = train_df_shuffle.iloc[(batchsize*j):min(batchsize*(j+1),
train_sample),:]
batch_input = batch['combine']
batch_input = np.array([i for i in batch_input.values])
batch_input = np.transpose(batch_input,(1,0,2))
tf_input = autograd.Variable(torch.FloatTensor(batch_input),
requires_grad=True)
# label
batch_label = batch['totals.transactionRevenue']
batch_label_reg = np.array([i for i in batch_label.values]).reshape(
(batchsize,1))
tf_label_reg = autograd.Variable(torch.FloatTensor(batch_label_reg))
batch_label_cf = np.array([1 if i > 0 else 0 for i in batch_label])
tf_label_cf = autograd.Variable(torch.LongTensor(batch_label_cf))
model.zero_grad()
loss, y_hat_cf, y_hat_reg = model.forward(tf_input, tf_label_cf,
tf_label_reg)
loss.backward()
optimizer.step()
epoch_loss += float(loss.data)
train_preds = np.concatenate((train_preds,y_hat_reg.view(-1).detach()
.numpy()), axis=0)
if j == 0: train_y = tf_label_reg.view(-1).detach().numpy()
else: train_y = np.concatenate((train_y,tf_label_reg.view(-1).detach()
.numpy()), axis=0)
losses.append(epoch_loss)
if verbose: print('epoch_loss', np.round(epoch_loss,4), end=' ')
# --- epoch MSE training
train_mse.append(mean_squared_error(train_y,train_preds))
train_rmse.append(np.sqrt(mean_squared_error(train_y,train_preds)))
if verbose: print('train_rmse', np.round(np.sqrt(mean_squared_error
(train_y,train_preds)),4), end=' ')
for j in range(0,iter_test):
test_batch = test_df.iloc[(batchsize*j):min(batchsize*(j+1),
test_sample),:]
test_batch_input = test_batch['combine']
test_batch_input = np.array([i for i in test_batch_input.values])
test_batch_input = np.transpose(test_batch_input,(1,0,2))
test_tf_input = autograd.Variable(torch.FloatTensor(test_batch_input),
requires_grad=True)
# label
test_batch_label = test_batch['totals.transactionRevenue']
test_batch_label_reg = np.array([i for i in test_batch_label.values])
.reshape((batchsize,1))
test_tf_label_reg = autograd.Variable(torch.FloatTensor
(test_batch_label_reg))
test_batch_label_cf = np.array([1 if i > 0 else 0 for i in
test_batch_label])
test_tf_label_cf = autograd.Variable(torch.LongTensor
(test_batch_label_cf))
test_loss, test_y_hat_cf, test_y_hat_reg = model.forward(test_tf_input
test_tf_label_f,
test_tf_label_reg)
test_preds = np.concatenate((test_preds,test_y_hat_reg.view(-1).detach
().numpy()), axis=0)
if j == 0: test_y = test_tf_label_reg.view(-1).detach().numpy()
else: test_y = np.concatenate((test_y,test_tf_label_reg.view(-1).detach
().numpy()), axis=0)
# --- epoch accuracy testing
test_mse.append(mean_squared_error(test_y,test_preds))
test_rmse.append(np.sqrt(mean_squared_error(test_y,test_preds)))
if verbose: print('test_rmse', np.round(np.sqrt(mean_squared_error(test_y,
test_preds)),4))
return losses, train_mse, train_rmse, test_mse, test_rmse
### read file
processed_train_df = pd.read_csv("processed_train_df.csv", dtype={'fullVisitorId':
'str'})
processed_train_df = processed_train_df.drop('Unnamed: 0', axis=1)
### 5-fold
unique_visitorId = processed_train_df['fullVisitorId'].unique()
random.seed(123)
random.shuffle(unique_visitorId)
no_cust = len(unique_visitorId)
print(no_cust)
fold = 5
id_cv = []
for i in range(fold):
if i < fold-1:
cur_cv = unique_visitorId[i*(no_cust//5):(i+1)*(no_cust//5)]
else:
cur_cv = unique_visitorId[i*(no_cust//5):no_cust]
id_cv.append(cur_cv)
### Vanilla RNN
print('\n\n\n# -- Vanilla RNN')
### param
print('\n\n# -- param')
num_layers=1
input_size=20
hidden_size=3
output_size=1
seq_len=6
epoch_num=7000
batchsize=1024
lr=0.0001
print('hidden_size',hidden_size,'num_layers',num_layers,'seq_len',seq_len)
### read sequential data
rnn_train = pd.read_csv("rnn_train.csv", dtype={'fullVisitorId': 'str',
'combine':'object'})
test_train = rnn_train['combine'].apply(strToList)
rnn_train['combine'] = test_train
rnn_train2 = rnn_train.copy()
rnn_train2['combine'] = rnn_train2['combine'].apply(lambda x: data_paddle(x,
seq_len).data_pad)
rnn_train2['totals.transactionRevenue'] = np.log1p(rnn_train2
['totals.transactionRevenue'])
### train model
cv_train_mse = []
cv_train_rmse = []
cv_val_mse = []
cv_val_rmse = []
fold = 5 #cv 1-5
for i in range(fold):
print('\nfold:', i)
#data
val = rnn_train2[rnn_train2['fullVisitorId'].isin(id_cv[i])]
train = rnn_train2[~rnn_train2['fullVisitorId'].isin(id_cv[i])]
train_df = train.iloc[:(train.shape[0] - train.shape[0]%batchsize),:]
test_df = val.iloc[:(val.shape[0] - val.shape[0]%batchsize),:]
losses, train_mse, train_rmse, test_mse, test_rmse =
run_trainer(train_df, test_df, num_layers, input_size,
hidden_size, output_size, seq_len, epoch_num,
batchsize, lr)
cv_train_mse.append(train_mse)
cv_train_rmse.append(train_rmse)
cv_val_mse.append(test_mse)
cv_val_rmse.append(test_rmse)
# -- Plot
plot_method = 'rnn'
plot_data = ''
plot_exp = 'cv'+str(fold)
plot_loss = True
plot_acc = True
loss = losses
train_perf = train_rmse
test_perf = test_rmse
get_plot(plot_method, plot_data, plot_exp, plot_loss, loss, plot_acc,
train_perf, test_perf)
print('\nAverage:')
print('train_mse_5fold', np.mean(cv_train_mse))
print('train_rmse_5fold', np.mean(cv_train_rmse))
print('val_mse_5fold', np.mean(cv_val_mse))
print('val_rmse_5fold', np.mean(cv_val_rmse))
### Weighted Classified Subnetwork for Regression
print('\n\n\n# -- Weighted Classified Subnetwork for Regression')
### param
print('\n\n# -- param')
seq_len=6
epoch_num=7000
lr=0.0001
param_reg = {}
param_reg['num_layers'] = 2
param_reg['input_size'] = 20
param_reg['batchsize'] = 1024
param_reg['hidden_size'] = 6
param_reg['output_size'] = 1
param_cf = {}
param_cf['num_layers'] = 2
param_cf['input_size'] = 20
param_cf['batchsize'] = param_reg['batchsize']
param_cf['hidden_size'] = 6
no_class = 2
print('param_reg:', param_reg,'\nparam_cf:', param_cf,'\nseq_len',seq_len,
'\nepoch_num',epoch_num,'\nlr',lr)
### read sequential data
rnn_train = pd.read_csv("rnn_train.csv", dtype={'fullVisitorId': 'str',
'combine':'object'})
test_train = rnn_train['combine'].apply(strToList)
rnn_train['combine'] = test_train
rnn_train2 = rnn_train.copy()
rnn_train2['combine'] = rnn_train2['combine'].apply(lambda x: data_paddle(x,
seq_len).data_pad)
rnn_train2['totals.transactionRevenue'] = np.log1p(rnn_train2
['totals.transactionRevenue'])
### train model
cv_train_mse = []
cv_train_rmse = []
cv_val_mse = []
cv_val_rmse = []
fold = 5 #cv 1-5
for i in range(fold):
print('\nfold:', i)
#data
batchsize = param_reg['batchsize']
val = rnn_train2[rnn_train2['fullVisitorId'].isin(id_cv[i])]
train = rnn_train2[~rnn_train2['fullVisitorId'].isin(id_cv[i])]
train_df = train.iloc[:(train.shape[0] - train.shape[0]%batchsize),:]
test_df = val.iloc[:(val.shape[0] - val.shape[0]%batchsize),:]
losses, train_mse, train_rmse, test_mse, test_rmse = train_rnnCF(train_df,
test_df, seq_len, epoch_num, lr, no_class, param_cf, param_reg)
cv_train_mse.append(train_mse)
cv_train_rmse.append(train_rmse)
cv_val_mse.append(test_mse)
cv_val_rmse.append(test_rmse)
# -- Plot
plot_method = 'rnn_wcf'
plot_data = ''
plot_exp = 'cv'+str(fold)
plot_loss = True
plot_acc = True
loss = losses
train_perf = train_rmse
test_perf = test_rmse
get_plot(plot_method, plot_data, plot_exp, plot_loss, loss, plot_acc,
train_perf, test_perf)
print('\nAverage:')
print('train_mse_5fold', np.mean(cv_train_mse))
print('train_rmse_5fold', np.mean(cv_train_rmse))
print('val_mse_5fold', np.mean(cv_val_mse))
print('val_rmse_5fold', np.mean(cv_val_rmse))