We used part of the dataset found in Kaggle, by filtering those Hip-Hop songs.
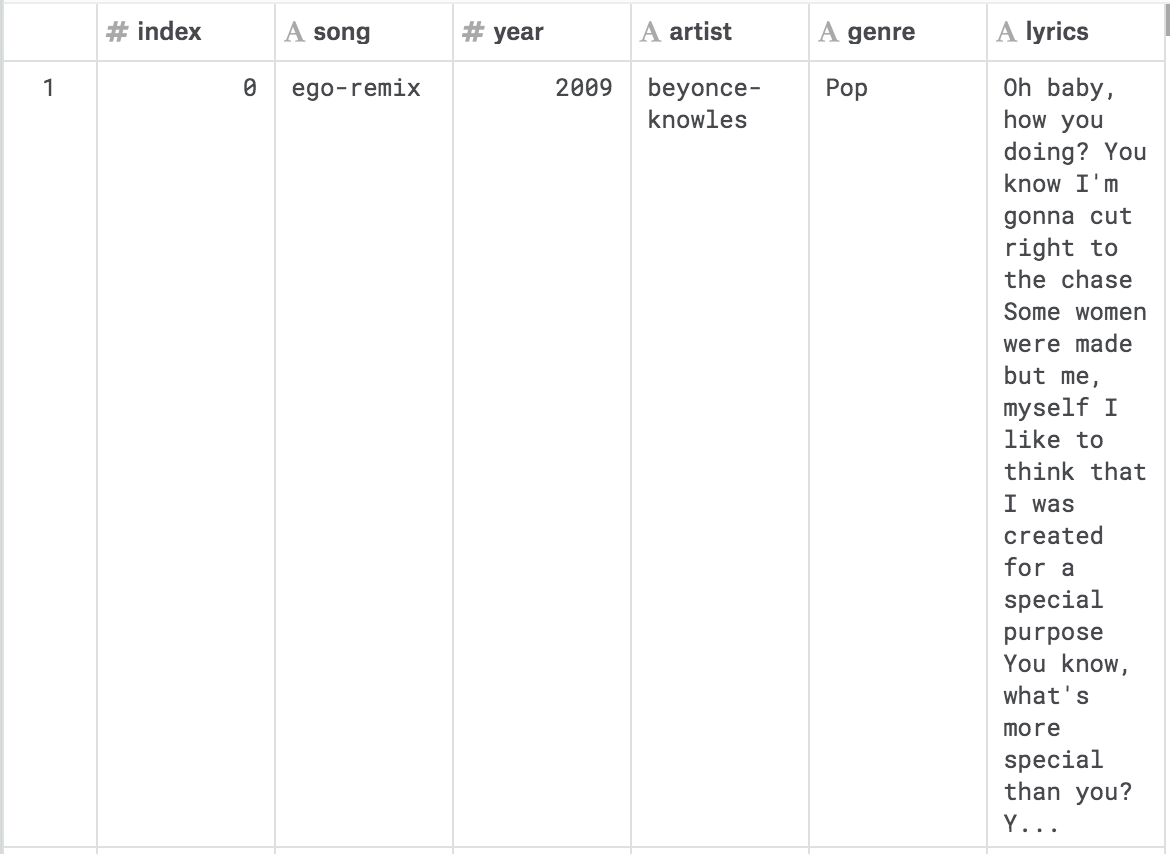
The structure of the original dataset is:
index: the unique integer to tag each song, will be reassigned after filtering;
song: string, the song’s name, words are connected by “-”;
year: integer, the year when the song was released;
artist: string, the artist’s name, words are connected by “-”;
genre: string, be assigned to equal “Hip-Hop” in filtering;
lyrics: string, the lyrics of each song, separated by lines, empty value will be deleted from the filtered dataset.
An example screenshot of the raw dataset:
number of lefted documents: 21866